Nel panorama in continuo fermento relativo alla gestione dei dati, una soluzione innovativa e all’avanguardia sta spopolando sempre di più in ogni angolo del mondo: parliamo, naturalmente, del data lakehouse. Questa particolare architettura nasce dall’esigenza di combinare la flessibilità del data lake con l’organizzazione strutturale di un data warehouse.
Un approccio ibrido, teso a soddisfare una pluralità di esigenze, facilitando processi di analisi avanzate e permettendo l’implementazione di modelli di machine learning.
Cos’è un data lakehouse e quali sono i suoi vantaggi? Scopriamo di più in questo articolo.
Indice dei contenuti
Cos’è un Data Lakehouse?
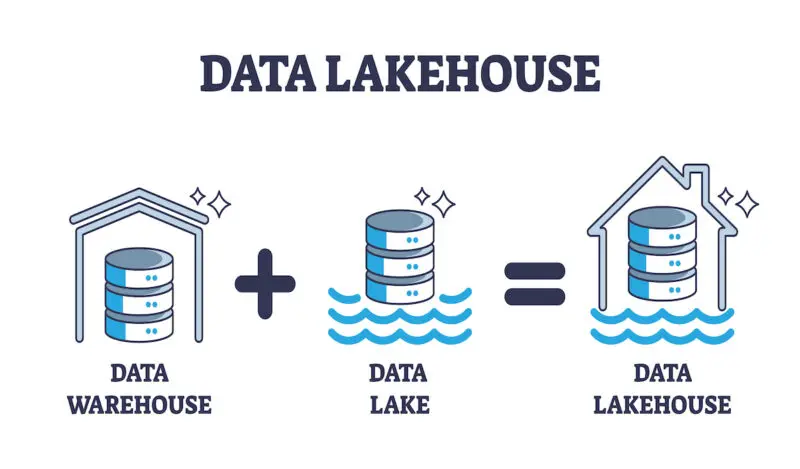
Un data lakehouse è una moderna piattaforma di dati, realizzata mediante la combinazione di un data lake e di un data warehouse. Questa architettura unifica e combina, in una sola piattaforma (molto spesso, su cloud), le potenzialità e le capacità di un data warehouse e di un data lake.
Il data lake per gestione volumi dati permette di ridurre al minimo le ridondanze e di semplificare, sotto diversi punti di vista, le attività di data management: dal design dell’architettura all’ottimizzazione dei dati.
Il data lakehouse utilizza lo storage di dati altamente flessibile di un data lake, combinando questa capacità alle funzioni e agli strumenti di gestione tipici di un data warehouse. Implementa, quindi, entrambe le capacità all’interno di un sistema più vasto.
Architettura dei Data Lakehouse
Il data lakehouse è in grado di elaborare dati in streaming o altre categorie di dati, forniti da differenti risorse di dati aziendali. Per poter effettuare analisi integrate con strumenti di machine learning data analytics, il data lakehouse combina i pregi di data lake e data warehouse, vantando un’architettura unica ed estremamente efficiente.
Un data lakehouse può essere plasmato sulla base di tre diverse architetture, a seconda delle esigenze di flessibilità, scalabilità e gestione dei dati:
- architettura a medaglione, basata sulla distribuzione su più nodi utile a ottimizzare la scalabilità delle operazioni. Un approccio che permette di gestire grandi volumi di dati, in grado di favorire la ridondanza e la disponibilità elevata di dati;
- architettura a strati. Questa architettura organizza i dati in strati logici distinti, rendendo più semplice il processo di gestione e l’accesso alle informazioni. Questa struttura favorisce la separazione delle funzionalità, facilitando la navigazione e l’individuazione di dati specifici;
- architettura a microservizi, la quale suddivide le funzionalità in servizi indipendenti, in grado di offrire un’esperienza integrata e massima flessibilità.
L’architettura del data lakehouse può comprendere alcuni livelli funzionali sulla base delle esigenze aziendali. Di seguito alcuni esempi di livelli implementabili:
- inclusione batch, utilizzata per l’acquisizione di dati molto costosi o non in tempo reale;
- trasferimento di massa, utile per spostare grandi volumi di dati in batch, impiegando connessioni private o servizi dedicati;
- inclusione in tempo reale, che permette di includere i dati real-time da sorgenti in cloud oppure on-premise, assicurando una distribuzione non invasiva ed estremamente efficiente;
- ingresso ed elaborazione in streaming, che permette di includere data set in tempo reale, da diversi produttori di dati. Inoltre, arricchisce i dati in streaming, individua pattern e crea flussi persistenti;
- API, che consente di impiegare l’intelligenza derivante da tecnologie di machine learning e data science nell’ambito delle applicazioni, mediante endpoint API;
- gestione e controllo dei dati, utile per visionare asset tecnici e per la gestione dei metadati. Questo elemento garantisce massima sicurezza ed è basata su modelli zero-trust;
- sicurezza dei dati, la quale implementa un modello avanzato per la prevenzione delle violazioni. Il modello, inoltre, è teso a garantire la conformità normativa;
- analitica e servizio streaming. Una soluzione in grado di fornire dashboard per l’analisi real-time dei dati in streaming, per l’inclusione e l’elaborazione di flussi di dati ad alto volume o continui.
Come funziona e come si utilizza
Il data lakehouse rappresenta una soluzione completa per la gestione e l’analisi dei dati. Il funzionamento e l’utilizzo di tale sistema presuppongono alcune fasi:
- progettazione dell’architettura, che può essere a medaglione, a strati o a microservizi, e definizione dei requisiti specifici dell’organizzazione;
- raccolta dei dati da varie fonti, tra cui archivi storici, transazioni e flussi di dati real-time;
- archiviazione, un processo scalabile che avviene in un ambiente simile al data lake. I dati vengono conservati in formato grezzo e strutturato, in modo che possano mantenere la flessibilità indispensabile per le successive analisi;
- trasformazione e pulizia dei dati, che vengono modificati attraverso processi di elaborazione e data integration, mantenendo coerenza e qualità;
- gestione della governance. Per poter garantire veridicità, sicurezza e conformità ai dati, vengono applicate rigorose politiche di governance;
- accesso e analisi mediante strumenti di business intelligence, analytics e linguaggi di programmazione. Questi processi avvengono in modo estremamente veloce ed efficiente;
- raccolta dei risultati. Le informazioni estratte possono essere impiegate per il decision making o per successivi processi operativi.
Per poter utilizzare efficacemente un data lakehouse, inoltre, è fondamentale:
- effettuare un continuo processo di manutenzione e ottimizzazione delle prestazioni del sistema, sulla base delle esigenze aziendali;
- garantire una formazione coerente al personale, affinché sappia gestire efficientemente il data data lakehouse;
- implementare pratiche di gestione del cambiamento, in modo che il data lakehouse possa essere utilizzato agevolmente dal personale.
Un aspetto essenziale che aumenta la potenza del data lakehouse è la data virtualization. Questa tecnologia, infatti, permette all’utente di accedere ai dati e di interrogarli, qualsiasi sia la loro ubicazione fisica.
Grazie alla data virtualization è possibile usufruire di una vista logica unificata e di un livello di estrazione che permette l’esecuzione di analisi a prescindere dalla complessità dei dati. Le informazioni contenute nel data lakehouse diventano, mediante la data virtualization, più accessibili indipendentemente dalla loro collocazione fisica.
Vantaggi di un data lakehouse rispetto a un data warehouse o a un data lake
Un data lakehouse combina i pregi di un data lake ai vantaggi di un data warehouse. Rispetto a queste due architetture, inoltre, il data lakehouse permette di usufruire dei seguenti vantaggi:
- massima flessibilità nell’archiviazione dei dati, anche in formati grezzi e non strutturati;
- integrazione di elementi di strutturazione;
- prestazioni ottimali, come nel caso del data warehouse;
- eccellente capacità di organizzare big data analytics e grandi volumi di dati, garantendo velocità e scalabilità;
- riduzione del rischio di data swamp, frequente nei data lake. Questo rischio viene abbattuto grazie a processi di governance estremamente raffinati, che consolidano le risorse mediante uno schema aperto e standardizzato;
- garanzia di sicurezza e veridicità per i dati;
- riduzione del rischio di vendor lock-in, in quanto il data lakehouse può essere implementato su diversi ambienti cloud;
- processi amministrativi più snelli, in quanto il data lakehouse permette di accedere a dati consolidati e immediatamente, piuttosto di doverli estrarre dai dati grezzi;
- costi ridotti, poiché l’infrastruttura del data lakehouse separa la computazione dallo storage. Quando aumentano le esigenze di storage, quindi, non è necessario incrementare parallelamente la potenza computazionale.
Data lake vs data warehouse
Le aziende moderne sceglieranno un data lake o un data warehouse a seconda delle specifiche esigenze:
- se le analisi sono ben definite e la strutturazione dei dati risulta chiara, propenderanno per un data warehouse;
- se intendono mantenere la flessibilità pur gestendo dati eterogenei, sceglieranno un data lake.
Un data warehouse, infatti, è progettato per gestire dati altamente organizzati e strutturati. Risulta la soluzione ottimale per analisi ad hoc e per le attività di reporting. Contraddistinto da una struttura rigida, questo sistema garantisce eccellenti performance per query predefinite. Ma potrebbe risultare limitante nel caso si voglia analizzare dati non strutturati e, inoltre, non risponde tempestivamente alle esigenze di big data. Un data lake, al contrario, viene progettato per gestire immensi volumi di dati, di natura diversa, garantendo massima scalabilità e flessibilità. La natura non strutturata del data lake lo espone al rischio di data swamp, qualora la governance non venga adeguatamente gestita. Inoltre, la struttura aperta permette l’ingresso di dati non validati.